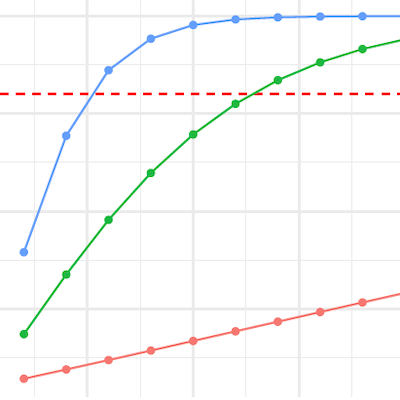
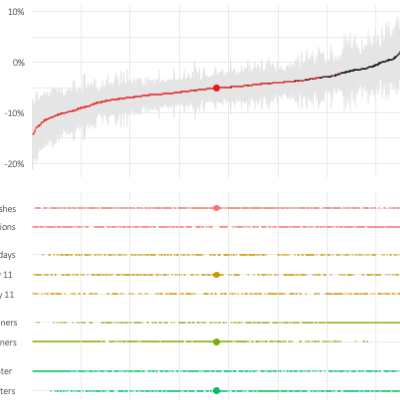
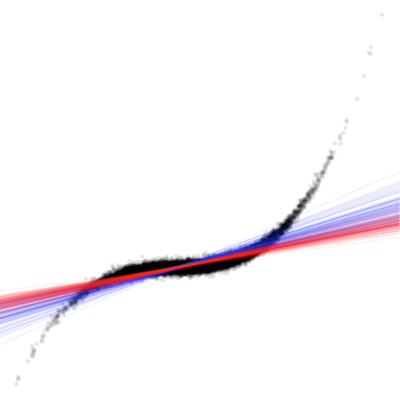
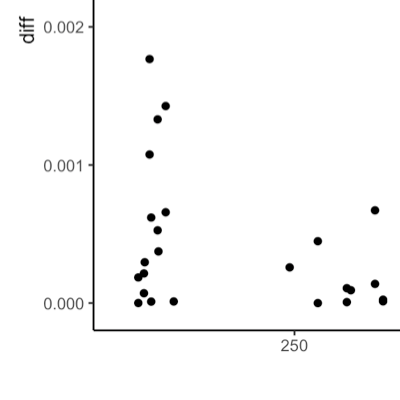
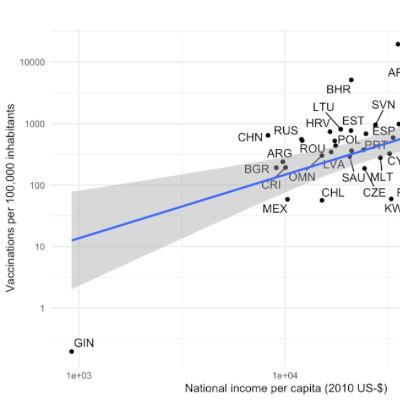
When you design experiments, you need to know how many participants it takes to get informative results. But what makes results informative? Simply put: A precise effect estimate, meaning an estimate that is unbiased and has a narrow confidence interval. Your randomized design and careful measurement should ensure that your effect estimate is unbiased. But how can you be confident that your estimate’s confidence interval is narrow ’enough'?