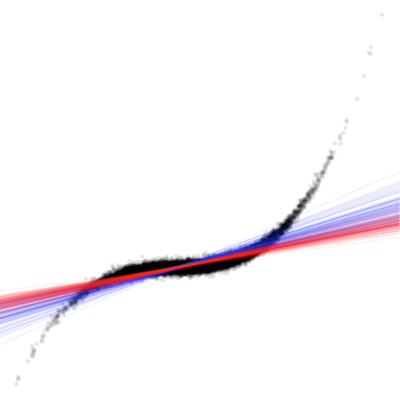
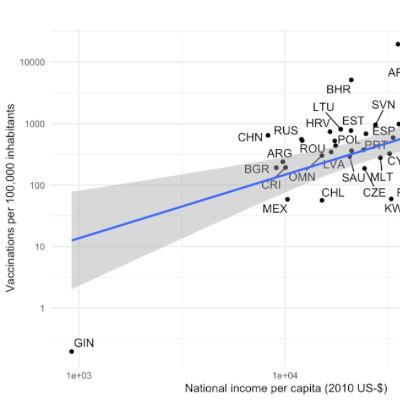
Building on a current working papers of David Veenman and myself, and using ‘fancy’ animations, we discuss the issues related to non-random outliers in empirical archival research work and whether robust regression methods can be viewed as a pancea (spoiler: they can’t). Building on these insights we suggest a work-flow for archival work that helps us to take outlier treatment to the next level.