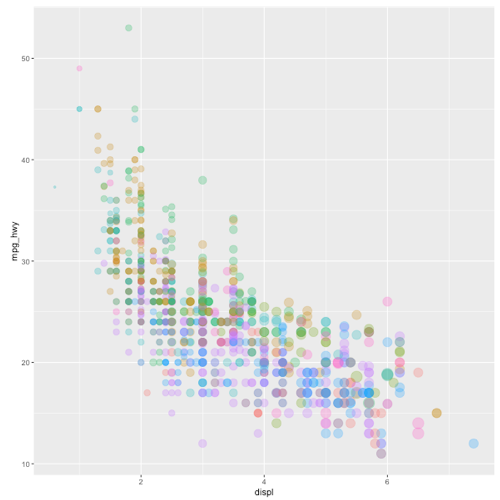
Interactive EDA is nice but customized interactive EDA is even nicer. To celebrate the new CRAN version of my ‘ExPanDaR’ package I prepare a customized variant of ‘ExPanD’ to explore the U.S. EPA data on fuel economy
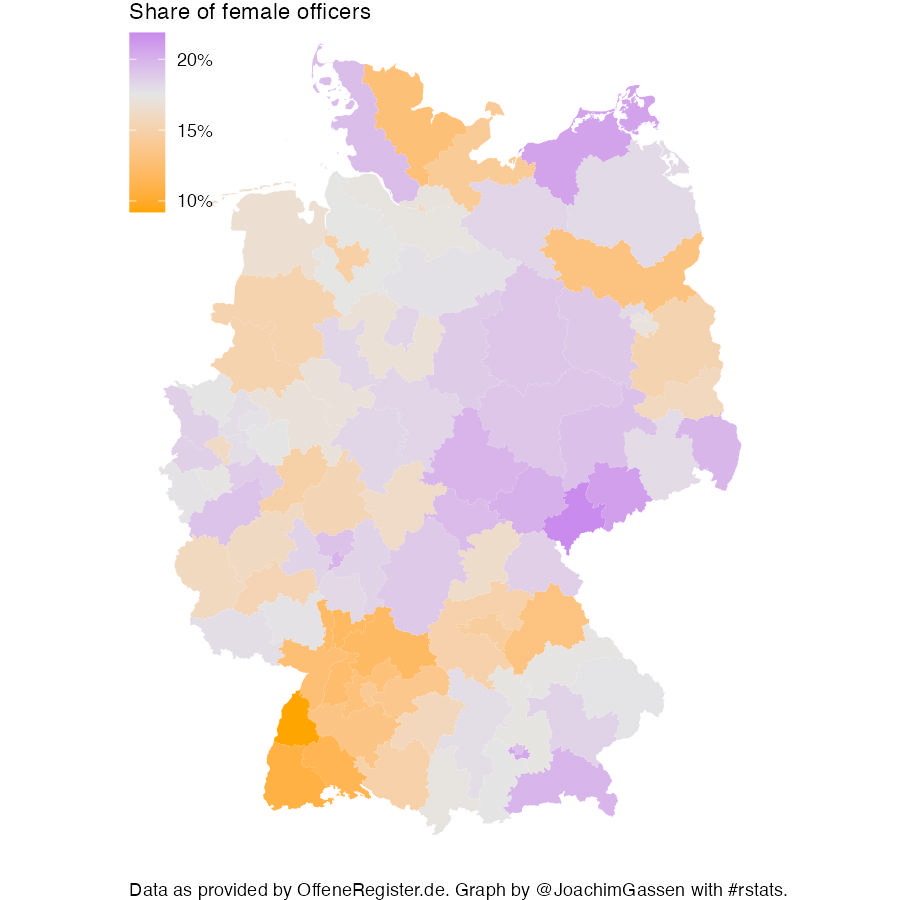
This a quick follow-up to my last post using German Trade Register data provided by offeneregister.de. This time I am picking up on an idea from Johannes Filter to locate female corporate officers.
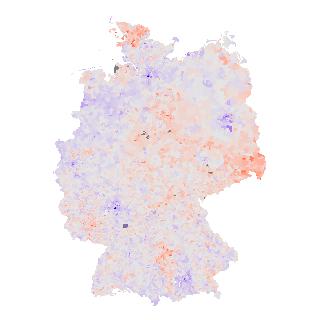
The Project OffeneRegister.de has recently made German Trade Register data more accessible. Let’s see whether R can help us to learn where the German companies are.